[icon name=”database” class=”” unprefixed_class=””] 数据:“最后我还想再拜托你一件事,希望你可以把我忘掉”
本人最近三个月之内经历了三次阵列崩溃,其中第一次损失了0.2TB,第二次算是因为第一次损失了一点点,第三次没有损失完美恢复
也是和阵列打交道多年了,也算是一点自己的经验之谈,给大家做参考。
[icon name=”exclamation-triangle” class=”fa-2x” unprefixed_class=””] 警告!!! 请根据自己实际情况以及数据重要性来选择如何处理和操作,不要一味的按照本教程执行,本人不对按照本教程操作丢失的数据负任何责任!![icon name=”exclamation-triangle” class=”fa-2x” unprefixed_class=””]
[icon name=”exclamation-triangle” class=”fa-2x” unprefixed_class=””] 在质保期内用户,请优先寻找官方工程师
[icon name=”exclamation-triangle” class=”fa-2x” unprefixed_class=””] 操作时请佩戴防静电手套或者手环,以免二次伤害!
[icon name=”exclamation-triangle” class=”fa-2x” unprefixed_class=””] 本教程仅适用于阵列完全进入Failed状态,而不是Degraded状态,如果在Degraded状态那么说明数据还可读,请优先将数据提取出来,再进行任何操作!
[icon name=”info-circle” class=”” unprefixed_class=””] 但是非官方硬盘就算了,找了也是白搭,不如说是找打,比如说买了DELL的服务器不用官方的硬盘自己买往上塞,搞不好会失去整机的质保,因为用了“非官方配件”
[icon name=”info-circle” class=”” unprefixed_class=””] 如果你看到了本文,那么有以下几种情况:励志成为专业运维;还没有经历过,想了解一下;经历过,但是没有完美解决;正在经历,不知道该怎么办。
[icon name=”info-circle” class=”” unprefixed_class=””] 不管是哪种情况,在这里需要声明的是,本文仅为本人的多年经验之谈,并非适用于所有情况,也不保证能100%恢复数据,请当作参考,或者走投无路时使用本教程。
[icon name=”info-circle” class=”” unprefixed_class=””] 既然选择这一行,那么就要时刻为这天准备着,必须要提前做好心理准备,作为运维最重要的一点就是稳重,万事切忌急,遇到事情第一件事不是陷入焦虑抑郁,而是想这么修复,怎么挽救,怎么补救,怎么把损失降到最小。
# Section End
[icon name=”info-circle” class=”” unprefixed_class=””] 常用知识(在开始/提问之前你需要知道的):
- 任何阵列(RAID0除外)在损失一块硬盘之后都会变成Degraded状态,如果损失超过RAID等级允许范围,阵列状态将会变成Failed状态。
- 为什么要说在Degraded之后要立即提取数据而不是马上开始rebuild呢?因为有很多人都是在rebuild过程中又损失了一块硬盘,彻底完犊子。。。
- 大多数人用来组阵列的硬盘都是一起购买的,也就是同厂商,同型号,同批次,同生产日期。这也就说明了一点,如果一块硬盘出现问题,那么其他一起买来的硬盘出现问题的可能性瞬间就翻倍,所以建议先提取数据,如果条件不允许,也请先提取重要数据
- 有人可能要说了,那我用不同批次不同厂商的硬盘不就行了? 否认,想都别想,不同厂商和批次的产品之间容易出现兼容性问题,以及各种奇怪的问题,更有可能导致阵列故障
- 不管因为什么,硬盘被拔出也好,掉盘也好,只要阵列卡和这个硬盘失去联系了,就会马上把这块硬盘标记为offlineh或者removed,并且发出警告。之后,就算这块硬盘重新插回来了,没换新,原样插回来了,也不会重新添加到阵列里,因为当这块硬盘掉盘的时候,阵列并没有Failed,系统仍然认为这个物理设备是完好无损的,所以仍会往里写数据,而这块被移除的盘呢,在移除的那一刻,就与整个阵列失去同步了,如果强行将这块硬盘加回来,那么会导致整个阵列数据不完整或者干脆就损坏
- 这可以理解为你打联机游戏,延迟大,如果只是掉线了一小会,那么游戏服务器会允许你重新加入到当前对战。但是如果你掉线时间太长了,服务器就会拒绝你重新加入到当前对战。阵列同理
- 一坨硬盘组成阵列之后是可以划分虚拟磁盘的,也就是比如说4TB*3, RAID5,总共是8TB出来,但是这8TB你可以划分成1TB和7TB两个虚拟磁盘。这个虚拟和物理是相对的,对于阵列卡来讲,只有这坨硬盘才是物理的,这些磁盘组成的阵列划分出的磁盘是虚拟的;而对于系统来讲,阵列卡划分出的虚拟磁盘是物理磁盘,系统就把一个VD当作一个物理设备来对待,在Linux系统上,第一个磁盘就是sda,第二个就是sdb,也就是说上面在阵列卡上划分出来的1TB和7TB的虚拟磁盘,在Linux系统下是一个sda一个sdb,两个独立的物理设备。
- 在DELL 13G服务器之后,也就是PERC H730P之后的型号,在掉了一块硬盘之后会尝试去reset这块硬盘,看看能不能救活,就和CPR一样,如果救活了,就上线开始同步数据,这个我很喜欢(当然大部分时间并不管用,有一个版本的firmware还会导致死循环,结果前年有一次reset了上百万次,直接把阵列卡给整挂了)
# Section End
[icon name=”ban” class=”” unprefixed_class=””] 阵列崩了之后的禁忌:
- 切记不能慌张,让自己冷静下来
- 不要立即重新启动或者关机放置一段时间重开,期待他自己就好了,不要抱有这种搞笑一样的期待!!
- 无法马上到现场,不要通过IPMI远程进行操作,可以检查情况,但是不能对阵列进行任何操作
- 切忌盲目操作,满脑子骚操作
- 阵列恢复后,切忌使用fsck或者xfs_repair进行修复(最后会讲到为什么)
- 切忌省钱,不要用移动硬盘等移动设备来dump数据,速度慢且不稳定,当然数据量很小的话也是可以的
# Section End
[icon name=”circle-o-notch” class=”” unprefixed_class=””] 在外地,阵列崩了之后可以做的事情:
[icon name=”exclamation-triangle” class=”fa-2x” unprefixed_class=””] 在本地也请先进行以下步骤
人在外地,够不着服务器,阵列崩了,怎么办。这可不是说RAID5损坏了一块硬盘,让机房人员换一块就行了,也不是CPU内存什么的坏了关机让现场人员换上就行了
这可是阵列崩了,数据全都要丢了,老婆们要丢了!
除非现场有高水平人才,且可以信任,否则不要让非专业人员进行操作。
- 登陆IPMI,查看情况,比如DELL从12代服务器之后就支持从iDRAC中查看磁盘和阵列情况了,先看是哪几块硬盘offline或者removed,按顺序记下来
- 计算数据损失,这个阵列上放的什么东西,放了多少,重要程度,提取数据的时候哪些重要哪些不重要,哪些先提取哪些后提取,这些都要做好打算,最后用纸笔写下来
- 关机,放置,防止进一步恶化或者损坏
- 准备好更换件,准备好dump数据的硬盘再去机房,根据数据量的大小,购买硬盘用来存放提取出的数据
- 如果情况比较严重,请准备好食物和水,最好是巧克力或者士力架这样高热量的东西,做好过夜的准备
- 一切工作准备完毕,脑子里有Roadmap了,手机或者纸上给自己写出todo了,好,订最近的长途/火车/高铁/飞机票,收拾好东西速度到现场
回想自己最近做过什么坏事观看《末日时在做什么?有没有空?可以来拯救吗?》
# Section End
[icon name=”random” class=”” unprefixed_class=””] 到现场之后,要干的事,和禁忌:
- 不!要!慌!张!
- 先检查服务器有没有被物理上动过手脚,比如说被人恶意拔插硬盘。(所以说为什么要前面板,托管出去必须要有前面板,别说什么都是专业人员不会干坏事,谁知道有没有疯子,干这行又不需要精神鉴定)
- 物理上检查完之后,请将服务器下架,移至维护区域
- 此时服务器一定是关机的,如果你按照上面的做了的话,这样你就无法看到哪块硬盘故障了。这时候就要拿出你之前记下的,哪块硬盘故障了,是什么故障
- 在关机,断电状态下,取出出现问题的硬盘,观察是否有物理损伤。短路,过热痕迹,凹陷等。检查外观没有问题后将其重新插入
- 打开机盖,检查线路,检查阵列卡是否有损坏痕迹,以及任何其他组件的任何故障痕迹,可以拔插一下线缆
- 确保所有线路已连接并且牢固后,关上机盖,开机
- 进入阵列卡BIOS,查看情况
# Section End
[icon name=”info-circle” class=”” unprefixed_class=””] 这里分为两种情况,第一种是老型号阵列卡,一般如果之前被removed掉的硬盘在重新检测到之后会变成offline状态;第二种是个别新型号阵列卡,在重新检测到硬盘之后会变成Foreign
先讲第一种,也就是我第一次崩的时候
[icon name=”repeat” class=”” unprefixed_class=””] 开始着手修复(案例1):
环境: DELL PowerEdge R510, 阵列卡:DELL PERC H700, 磁盘希捷Ironwolf系列4TB*3 (其他磁盘在此不提)
当时的DELL iDRAC日志:
| Critical | Mon Dec 13 2017 17:08:40 | Fault detected on Drive 7. | ||
| Critical | Wed Dec 13 2017 17:24:22 | Fault detected on Drive 8. | ||
下午5点,连着崩盘,收到警告之后还没等反应直接炸了,但是这是存储,并不是系统盘
所以当时系统内xfs刷的错误:
root@****:/var/log# cat messages | grep sdb
Dec 13 17:24:40 **** kernel: [6527894.552003] sd 0:2:1:0: [sdb] Unhandled error code
Dec 13 17:24:40 **** kernel: [6527894.552019] sd 0:2:1:0: [sdb]
Dec 13 17:24:40 **** kernel: [6527894.552026] sd 0:2:1:0: [sdb] CDB:
Dec 13 17:24:40 **** kernel: [6527894.552254] XFS (sdb): xfs_do_force_shutdown(0x2) called from line 1172 of file /build/linux-1wJOX9/linux-3.16.43/fs/xfs/xfs_log.c. Return address = 0xffffffffa05eeede
Dec 13 17:24:40 **** kernel: [6527894.552399] sd 0:2:1:0: [sdb] Unhandled error code
Dec 13 17:24:40 **** kernel: [6527894.552403] sd 0:2:1:0: [sdb]
Dec 13 17:24:40 **** kernel: [6527894.552411] sd 0:2:1:0: [sdb] CDB:
Dec 13 17:24:40 **** kernel: [6527894.552488] sd 0:2:1:0: [sdb] Unhandled error code
Dec 13 17:24:40 **** kernel: [6527894.552490] sd 0:2:1:0: [sdb]
Dec 13 17:24:40 **** kernel: [6527894.552493] sd 0:2:1:0: [sdb] CDB:
Dec 13 17:24:40 **** kernel: [6527894.552566] sd 0:2:1:0: [sdb] Unhandled error code
Dec 13 17:24:40 **** kernel: [6527894.552568] sd 0:2:1:0: [sdb]
Dec 13 17:24:40 **** kernel: [6527894.552571] sd 0:2:1:0: [sdb] CDB:
Dec 13 17:24:40 **** kernel: [6527894.552829] XFS (sdb): xfs_do_force_shutdown(0x2) called from line 1172 of file /build/linux-1wJOX9/linux-3.16.43/fs/xfs/xfs_log.c. Return address = 0xffffffffa05eeede
Dec 13 17:24:40 **** kernel: [6527894.552883] XFS (sdb): xfs_do_force_shutdown(0x2) called from line 1172 of file /build/linux-1wJOX9/linux-3.16.43/fs/xfs/xfs_log.c. Return address = 0xffffffffa05eeede
Dec 13 17:24:40 **** kernel: [6527894.552936] XFS (sdb): xfs_do_force_shutdown(0x2) called from line 1172 of file /build/linux-1wJOX9/linux-3.16.43/fs/xfs/xfs_log.c. Return address = 0xffffffffa05eeede
Dec 13 17:24:45 **** kernel: [6527924.632465] XFS (sdb): xfs_log_force: error 5 returned.
Dec 13 17:25:45 **** kernel: [6527954.713584] XFS (sdb): xfs_log_force: error 5 returned.
Dec 13 17:25:46 **** kernel: [6527984.794638] XFS (sdb): xfs_log_force: error 5 returned.
# ...
嗯,系统直接乱套了,到了之后系统已经关机了,硬盘拔下来看看没有问题插回去
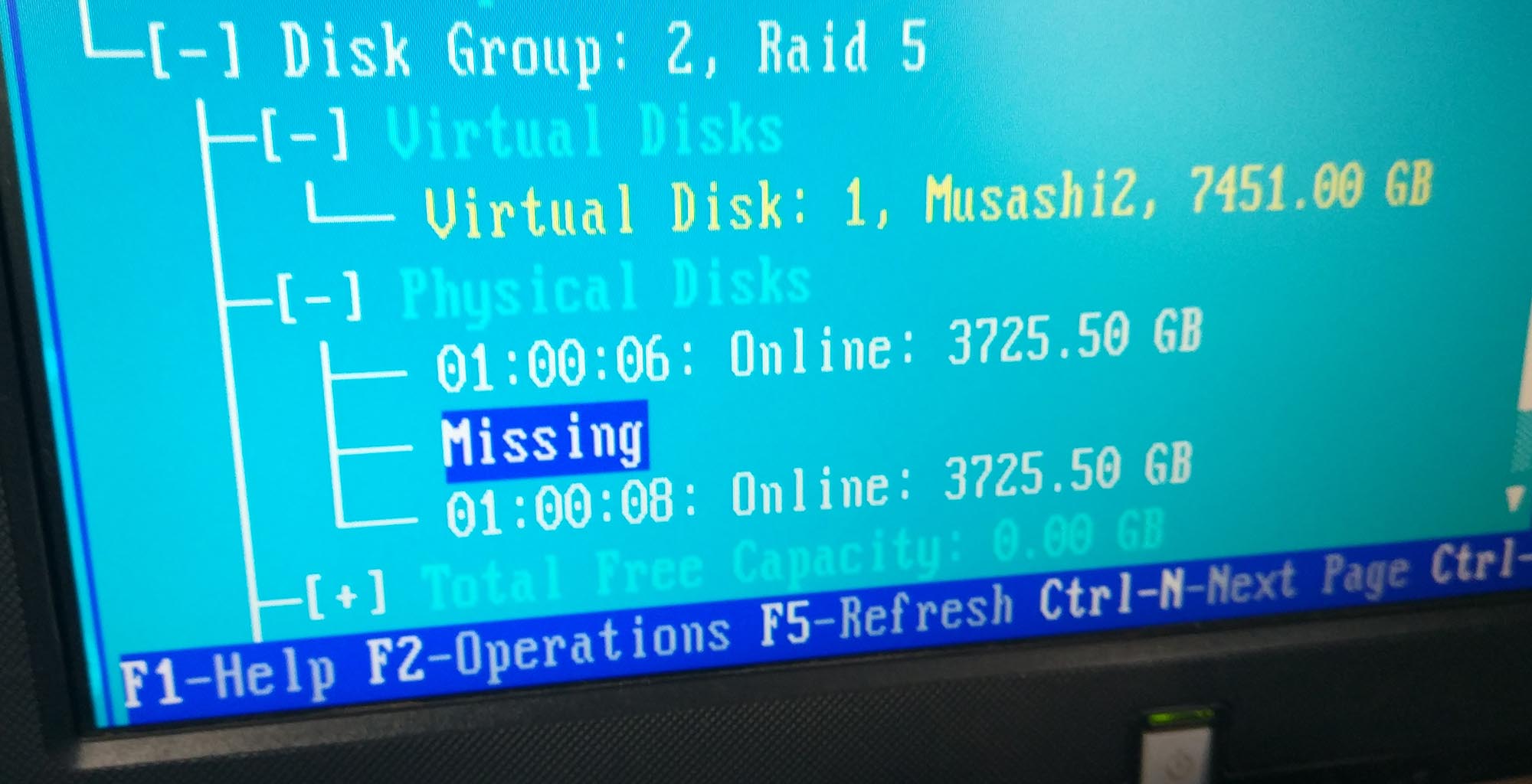
进入阵列卡BIOS
实际上当时是7和8都没了,整个阵列是红的Failed掉了
后来我强行上线了Disk 8
[icon name=”balance-scale” class=”” unprefixed_class=””] 这里要讲为什么要上线08,这是整篇文章的一个我要表达的核心思想
拿这个案例来讲,三块硬盘是RAID5阵列的最低要求,所以我们就拿这个最简单的模型来讲
三块硬盘,分别是Disk 6, Disk 7, Disk 8
一开始三块硬盘都在正常工作,可以fail一块,也就是Redundancy为1
啪,Disk 7不知道为什么,突然没了,直接扔了一个错误,跑路了。
但是不要紧,RAID5可以损失一块硬盘,系统也认为这个物理设备在正常工作,因为他还可写可读,也没有SMART信息,阵列卡也不会告诉系统我这损失了Redundancy你别写了,所以系统仍然在往阵列中写入数据。
但是,啪,Disk 8也不知道为什么,突然没了,也扔了一个错误,跑路了。
这样RAID5阵列整个就报废了,进入Failed状态,系统也意识到这个设备不可读写了,xfs就也炸了,在内存里面的数据,阵列卡缓存里面的数据肯定也都没法写到磁盘里了,所以这一部分数据是肯定要丢的。
[icon name=”fire” class=”” unprefixed_class=””] 现在,整个阵列的数据都不可读了,都完蛋了,你系统里也看不到了,阵列卡里也显示Failed了,一首凉凉送给自己
但是还没完啊!我们还能挽回数据!!!只要硬盘没有物理损伤!!只有这货还能加载磁头!!阵列卡还能认出这块硬盘!就完全大丈夫!
为什么要上线Disk 8而不是Disk 7,想必各位看完我前面的话就知道为什么了吧
因为Disk 7先掉线,很多数据根本就没同步写入到Disk 7中,所以Disk 7跟Disk 6, Disk 8中存储的数据就差的太远了
如果我选择强行上线Disk 7而不是Disk8的话,那么绝对会造成巨大的数据不一致(断片)以及肯定的数据丢失
但是如果上线Disk 8就不一样了,因为他掉线之后整个阵列就不可写也不可读了,所以也不会有新数据写入到阵列中,这时候Disk 6和Disk 8中的大部分数据是同步的,会有极少的不一致性(inconsistency)
所以我选择强行上线Disk 8,而不是Disk 7
[icon name=”info-circle” class=”” unprefixed_class=””] 需要注意的是,就算是这样,在Operation中选择Force Online的时候也会提示会造成数据不一致性以及潜在的数据丢失的可能性。
强行上线之后,阵列变成黄色, Degraded状态。重启进入系统,mount文件系统,开始转移数据
//我去之前买了一块4TB的西数,带过去配好RAID0开始倒数据
[icon name=”paper-plane” class=”” unprefixed_class=””] 总体思路:
在处理这种磁盘阵列损坏的情况的时候,首先不要慌,评估当前的状态
到场之后确认是不是硬件损坏,如果物理损坏的硬盘数,大于阵列可容忍的数量,那么基本上真的是没救了,如果是公司数据而且公司贼有钱的话,那需要去找开盘提取数据再重新组阵列,而且成功率也不高
非硬件损坏相对于来说更好办,思路就如上所述
强行上线最近掉的一块盘,以此类推,按照硬盘消失的顺序强行上线,
[icon name=”exclamation-triangle” class=”fa-2x” unprefixed_class=””] 当然间隔时间太长的硬盘就不要强行上线了,妥妥的数据不一致
# Section End
[icon name=”repeat” class=”” unprefixed_class=””] 开始着手修复(案例2):
环境: DELL PowerEdge R730xd, 阵列卡:DELL PERC H730P, 磁盘:Intel 240G SSD*6 (其他磁盘在此不提)

//上图Disk 2被我手动拔出来了,为了防止import configuration的时候一起带进去
这次崩溃没有损失任何数据,有一定的运气成分在里面
这次同样是掉了两块盘,第一块掉了之后收到警告邮件马上开始转移数据,转移到一半又一块炸了
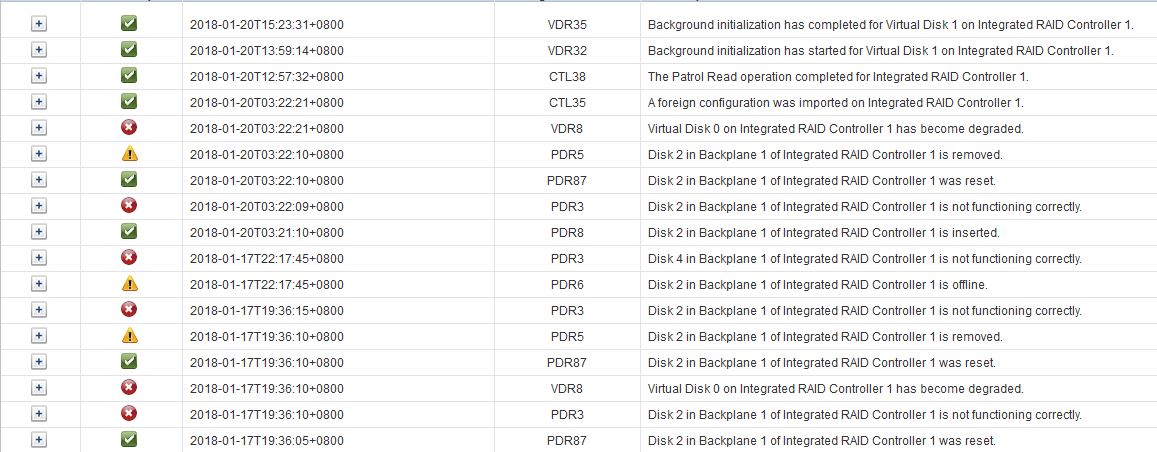
这次没截阵列卡的图,拿Lifecycle Log来看看吧,直接Log Type: Storage filter走起
顺序从下往上看,1月17号下午7点36分Disk 2挂了,阵列Degraded,之后阵列卡反复重试reset Disk2
这个消息很有意思,提示工作不正常之后让你去手动拔插一下看看行不行,不行就换硬盘,唉,时代变了,上面那个PERC H700如果拔了插回去就炸毛了,这个还主动让你拔插
PDR3: Disk 2 in Backplane 1 of Integrated RAID Controller 1 is not functioning correctly.
Detailed Description:The RAID Controller may not be able to read/write data to the physical disk drive indicated in the message. This may be due to a failure with the physical disk drive or because the physical disk drive was removed from the system.Recommended Action:Remove and re-insert the physical disk drive identified in the message and make sure the physical disk drive is inserted properly. If the issue persists, replace the physical disk drive.然后当天晚上10点多点,Disk 4挂了。。。。。。。。。。。
然后我不在现场就先把机器关了,然后上个周我还在感冒发烧,等到20号周末病还没好就打包跑过去了
[icon name=”exclamation-triangle” class=”” unprefixed_class=””] 前面为什么说不要尝试在远程轻举妄动,因为真的贼危险啊,一开始Disk 2掉了之后,阵列卡就标记offline了,结果一重启Disk 2成removed了,Disk 4掉了offline。最后我20号在现场看的时候, Disk 2和Disk 4都成外来户(Foreign)了???????
[icon name=”exclamation-triangle” class=”” unprefixed_class=””] 注意在DELL PERC H730P这种现代阵列卡上,和之前有点不一样,他可以Force online,但是只要他认为你这块盘被拔出去干过其他事,同时又保留着RAID阵列信息,就会认为这块盘是Foreign configuration
这时候不要担心,大胆往前走,直接import foreign configuration,不会覆盖掉剩下这4块盘的阵列,因为剩下这4块盘的标记也留在这个“外来户”的户口里
[icon name=”exclamation-triangle” class=”” unprefixed_class=””] 需要注意,因为Disk 2是先掉的,如果你import foreign configuration的话,因为这俩foreign是一伙的,所以会把Disk 2也拉上一起import,你没有选择的余地,选择import哪个不import哪个,因为阵列卡看来这俩是一个阵列里的,要import就一起import
所以我先关机,把Disk 2拔出来, 开机,import foreign configuration, 进系统,倒数据,导出配置文件,重新做阵列,重新做系统,导入配置文件,重新连接iSCSI,导入数据,完事
当天搞定,中午我爸出去买了盘饺子回来,下午就美滋滋回家了
# Section End
[icon name=”lock” class=”” unprefixed_class=””] 一定不要用fsck或者xfs_repair来修复文件系统:
在强行上线硬盘之后,阵列和虚拟磁盘对于系统来讲就是一个看起来正常运转的物理设备了,这时候就可以读取数据了,所以一定要趁现在读取数据。
来讲两个案例,为什么不要运行fsck或者xfs_repair
[icon name=”file-o” class=”” unprefixed_class=””] 案例1(ext4):
我们当时在LA又基础设施,当时有一台核心服务器炸了,也是磁盘的问题,最后拖出来的数据七零八碎的,都没眼看了
当时我们家开发在那拖数据,都是些虚拟机镜像和虚拟磁盘,然后就有一台数据库的虚拟机损坏的特别严重
拖出来之后开机,系统是能进去,但是数据库起不起来了,MySQL Server直接扔一坨错误exit,然后我们家开发就
跑了一波fsck!!!!!!!(reboot 到rescue里)
10个多G的数据啊!!!!fsck完了之后就剩几百兆!!!系统都启动不起来了!!!!
当时大晚上的差点气得我一口血喷屏幕上,这真的是数据连渣渣都不剩了
[icon name=”exclamation-triangle” class=”” unprefixed_class=””] 所以这样恢复出来的磁盘,不管是虚拟磁盘(虚拟化)还是虚拟磁盘(阵列)都不要去跑fsck,真的会literally毁掉你的数据
后来又重新拖了一份虚拟磁盘,我进去之后把innodb修了一波,dump,拿走,恢复,搞定
所以说有些文件系统层面的东西他根本不管你应用层面的数据,他只管这个地方数据怎么怎么,那个地方数据怎么怎么,只要移动到他觉得对的地方就成了
数据库呢,数据库绝对是我见过最耐造的,这虚拟磁盘真的数据都成渣了,系统能起来都是奇迹了,居然innodb还能修好数据库然后完好无损的dump出来,然而如果要fsck修复文件系统的话,那MySQL的数据库文件就会彻底被损坏
# Section End
[icon name=”file-o” class=”” unprefixed_class=””] 案例2(xfs):
这就是上面那第一个案例我恢复的时候犯了个天大的错误
我现在真想回去给我一个大耳刮子
这坑我踩了,写出来希望看到的人不要再犯这样的错误
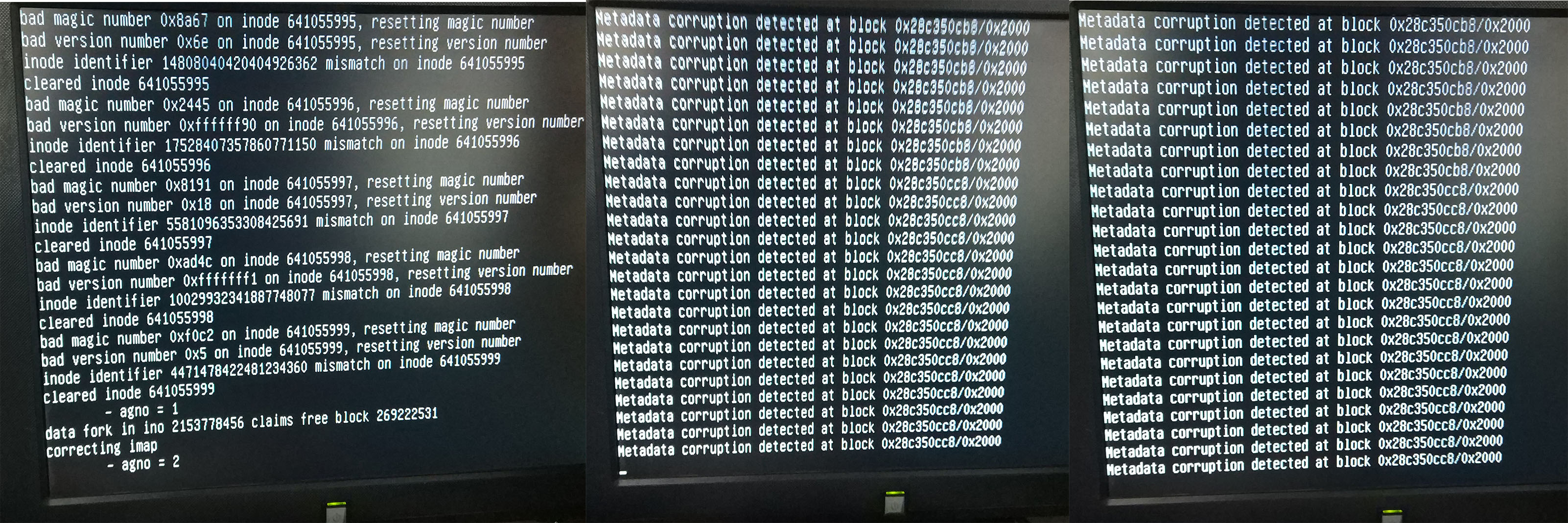
和fsck一样,直接一坨检测到corruption然后就修复,然后修不了的就拖出来扔到lost+found去
最后修复前3.7T,修复后3.5T,lost+found里面就300多MB,还全都是乱码文件,没有后缀,完全无法恢复
然后这也不是虚拟机的磁盘可以再重来,没了就没了。。。
所以我建议大家,先把数据拖出来再说,起码你拖出来了,哪个坏了你能知道是哪个文件损坏了,可以去找备份什么的
这一个xfs_repair直接没了,而且你还不知道他删了哪些,也不给你个manifest
# Section End
嘛,到这里就结束了,希望能帮到大家。也感谢能看到这里的人ww
如果还有什么想让我说说的就在下面给我留言,或者微博上私信我也可以,刚好在放假可以写点经验之谈
#########################################################

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
#########################################################
抱歉⋯我已经 绝对不可能再获得幸福了
因为⋯我发现⋯
其实我⋯
早就已经被幸福包围了
——珂朵莉·诺塔·瑟尼欧里斯《末日时在做什么?有没有空?可以来拯救吗?》
[icon name=”external-link” class=”” unprefixed_class=””] Wikipedia: 末日时在做什么?有没有空?可以来拯救吗?